Large Language Model (LLM) Development in Cloud Computing Environment - Part 1: Data Preprocessing & Feature Engineering using Apache Hadoop
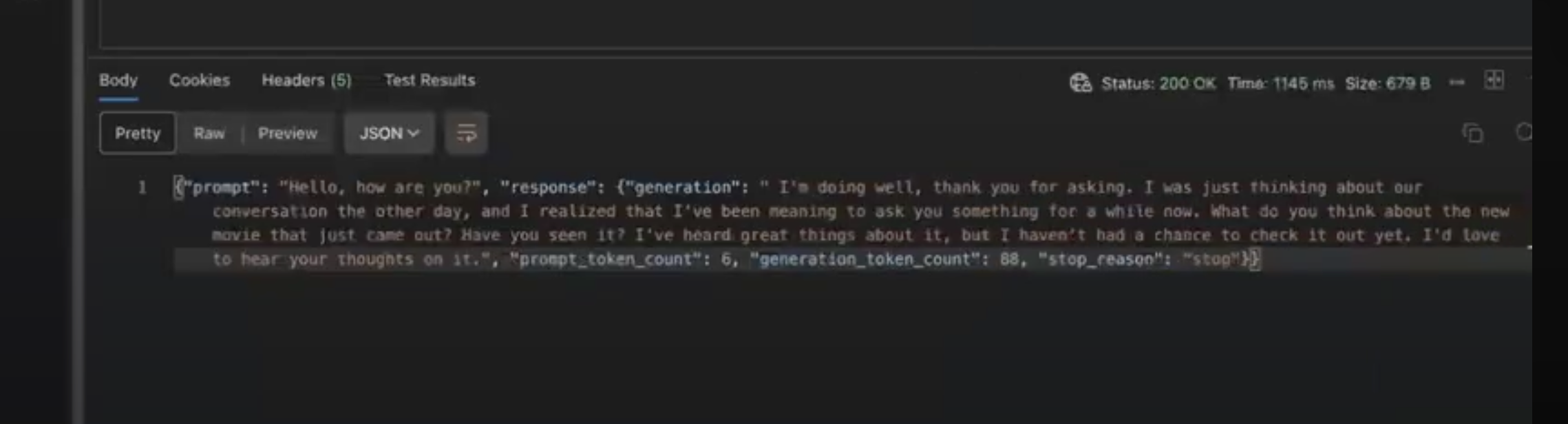
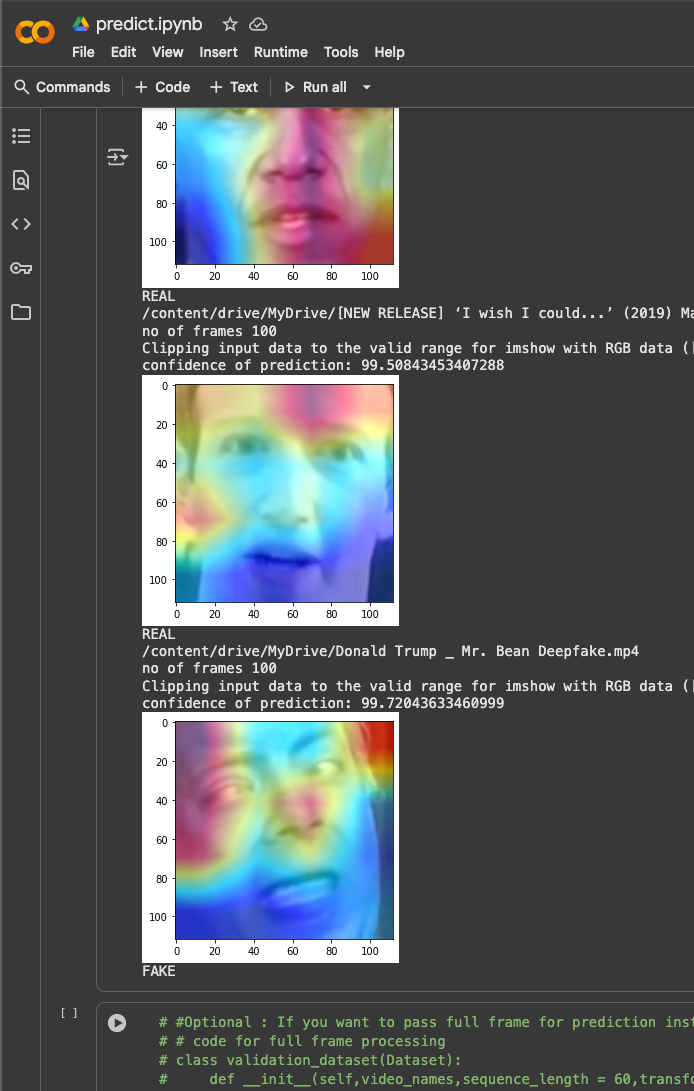
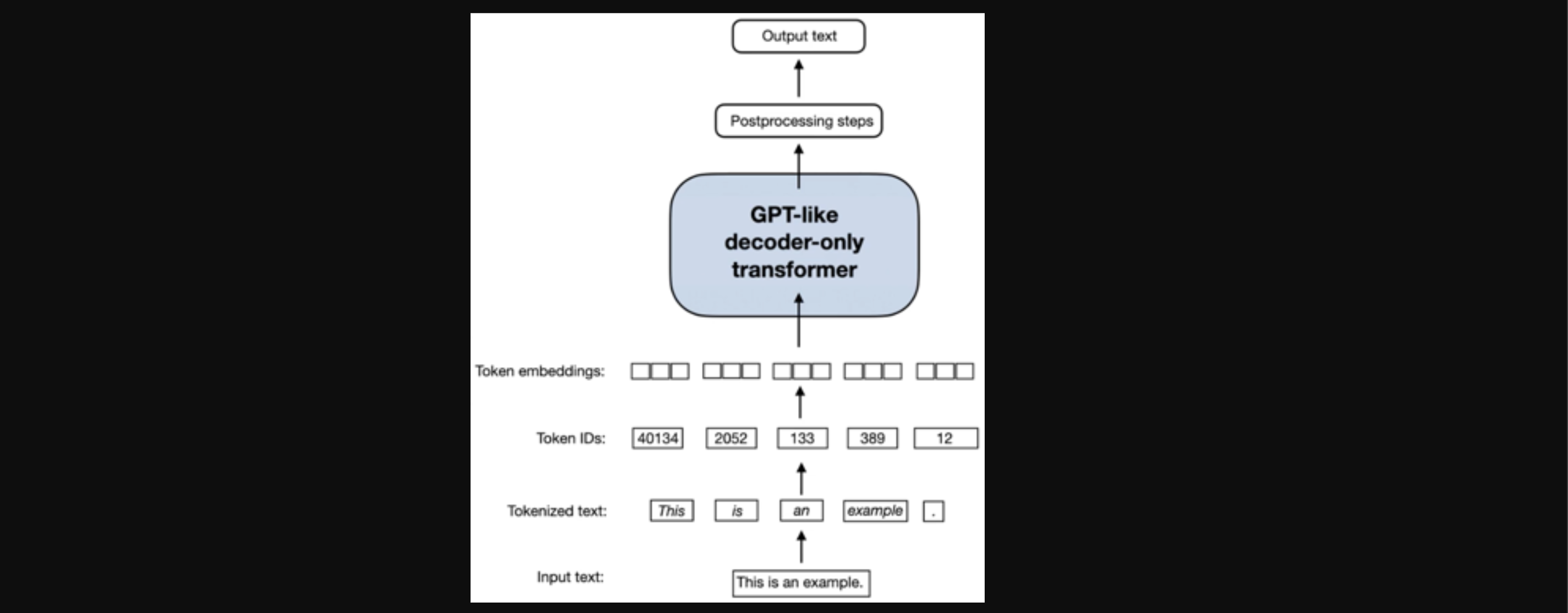
Designed and implemented a distributed data preprocessing pipeline using Apache Hadoop and Apache Spark. The process involved creating a Byte Pair Encoding (BPE) tokenization system and a Word2Vec model to generate high-quality word embeddings from a large text corpus. The solution was deployed and executed on Amazon EMR, with a focus on optimizing embedding dimensionality for large-scale, distributed environments.
ScalaJTokkitWord2VecApache HadoopMap/Reducedeeplearning4jAWS EMRAWS S3configSLFL4J